Hinweise zur 13.Übung: ![]() - und
- und ![]() -Fehler,
KS-Test und MW-Vergleiche
-Fehler,
KS-Test und MW-Vergleiche
1.]
Wir stellen uns folgende Situation vor: Eine Münze sei entweder
"ehrlich", d.h.
![]() ,
oder gewichtsmäßig unsymmetrisch mit
,
oder gewichtsmäßig unsymmetrisch mit
![]() , und
, und
![]() .
Durch
.
Durch ![]() Stichproben für
Stichproben für ![]() soll dies geklärt werden. Dabei
sei als kritischer Wert
soll dies geklärt werden. Dabei
sei als kritischer Wert ![]() =0.4 gewählt, der Mittelwert von
=0.4 gewählt, der Mittelwert von
![]() und
und ![]() . Wie groß muß der
Stichprobenumfang
. Wie groß muß der
Stichprobenumfang ![]() sein, um bei
sein, um bei
![]() als kritische Grenze
der Stichprobe eine 95%-ige Sicherheit
gegen den
als kritische Grenze
der Stichprobe eine 95%-ige Sicherheit
gegen den ![]() -Fehler zu haben? Ist dies wegen der Symmetrie
von
-Fehler zu haben? Ist dies wegen der Symmetrie
von ![]() dann auch die analoge Grenze des
dann auch die analoge Grenze des ![]() -Fehlers nach unten?
Begründen Sie die Aussage und versuchen Sie eine Lösung mit SPSS!
-Fehlers nach unten?
Begründen Sie die Aussage und versuchen Sie eine Lösung mit SPSS!
Wenn der Stichprobenumfang ![]() größer wird, wird die Varianz enger,
und die 5%-Grenze der Nullhypothese rückt näher an 0.5 heran.
Folgende Befehlsdatei ist ein erster Test für
größer wird, wird die Varianz enger,
und die 5%-Grenze der Nullhypothese rückt näher an 0.5 heran.
Folgende Befehlsdatei ist ein erster Test für ![]() .
.
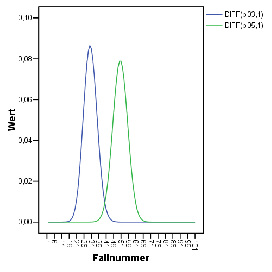
/* Aktiviere 101 Zeilen */ Input Program . LOOP #I=1 to 101 . Compute anzahl=#I . FORMATS anzahl (F8). END CASE . END LOOP . END FILE . END INPUT PROGRAM . EXECUTE . /* Verteilungen und Dichten der beiden Faelle */ COMPUTE bi03 = CDF.BINOM($casenum,101,0.3) . EXECUTE . COMPUTE bi05 = CDF.BINOM($casenum,101,0.5) . EXECUTE . CREATE /bi03D=DIFF(bi03 1) /bi05D=DIFF(bi05 1). GRAPH /LINE(MULTIPLE)= VALUE( bi03D bi05D ) .Im DatenFenster kann man in der Spalte der Verteilungsfunktion bi05 der "ehrlichen" Münze ablesen, ob für
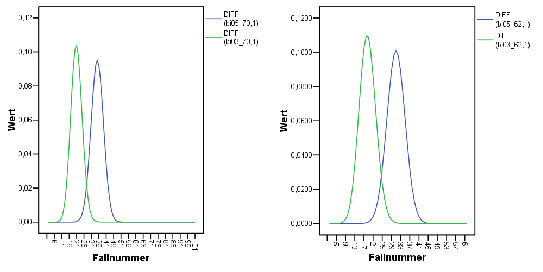
/* De-Aktiviere Zeilen 71-101, d.h. einfach loeschen */ COMPUTE bi03_70 = CDF.BINOM($casenum,70,0.3) . EXECUTE . COMPUTE bi05_70 = CDF.BINOM($casenum,70,0.5) . EXECUTE . CREATE /bi05_70D=DIFF(bi05_70 1) /bi03_70D=DIFF(bi03_70 1). GRAPH /LINE(MULTIPLE)= VALUE( bi05_70D bi03_70D ) .Es zeigt sich, dass
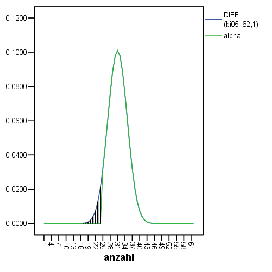
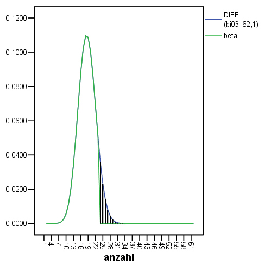
/* De-Aktiviere Zeilen 63-71, d.h. einfach loeschen */ COMPUTE bi05_62 = CDF.BINOM($casenum,62,0.5) . EXECUTE . COMPUTE bi03_62 = CDF.BINOM($casenum,62,0.3) . EXECUTE . CREATE /bi05_62D=DIFF(bi05_62 1) /bi03_62D=DIFF(bi03_62 1). GRAPH /LINE(MULTIPLE)= VALUE( bi05_62D bi03_62D ) .
Beim Wert ![]() =[0,4*n]+1=25 ist in der Datentabelle von bi05_62 nachzusehen,
ob die Verteilungsfunktion 0,05 ueberschritten hat;
bei 24 finden wir 4,9%, bei 25 dann 8,1%.
Also sollte der Stichprobenumfang 62 sein, und der kritische Wert einer
Strichprobe zur Ablehnung der Nullhypothese ist dann 24.
=[0,4*n]+1=25 ist in der Datentabelle von bi05_62 nachzusehen,
ob die Verteilungsfunktion 0,05 ueberschritten hat;
bei 24 finden wir 4,9%, bei 25 dann 8,1%.
Also sollte der Stichprobenumfang 62 sein, und der kritische Wert einer
Strichprobe zur Ablehnung der Nullhypothese ist dann 24.
Die Streuungen der beiden Hypothesen sind nicht gleich:
2.]
a) Erzeugen Sie mit Hilfe der Funktion RV.NORMAL 222 nach
N(0,1000) normalverteilte Zufallszahlen als Variable NN.
b) Zeichnen Sie mit Hilfe von STREUDIAGRAMM die empirische
Verteilungsfunktion von NN, sowie die theoretische Verteilungsfunktion von
N(0,1000), und bilden Sie die Differenz beider Funktionen.
c) Vergleichen Sie das Resultat mit dem Kolmogorov-Smirnov Test
für NN.
Man aktiviere 222 Zeilen und erzeuge NN=RV.NORMAL(NN,0,1000) .
Durch Sortieren von NN kann man mit
EmpVert = $casenum /222 die empirische Verteilungsfunktion erzeugen.
Der zu jedem NN gehörige Wert der "wahren" Verteilungsfunktion ergibt
sich durch direktes ![]() Berechnen als CDF-Funktion Vert = CDF.NORMAL(NN,0,1000).
(Man kann auch genauer die in SPSS berechenbaren realen Werte für
Mittelwert und Streuung von NN in die CDF einssetzen.)
Die Test-Statistik des KS-Tests ist dif=
Berechnen als CDF-Funktion Vert = CDF.NORMAL(NN,0,1000).
(Man kann auch genauer die in SPSS berechenbaren realen Werte für
Mittelwert und Streuung von NN in die CDF einssetzen.)
Die Test-Statistik des KS-Tests ist dif=
![]() =0,72566 . In
=0,72566 . In ![]() Nichtlineare Tests, KS-Test,
ergibt sich hier ein Signifikanzniveau von über 96%, also wird die
Zufallsverteilung von SPSS auch als Normalverteilung ausgewiesen.
Nichtlineare Tests, KS-Test,
ergibt sich hier ein Signifikanzniveau von über 96%, also wird die
Zufallsverteilung von SPSS auch als Normalverteilung ausgewiesen.
Der Test auf Normalverteilung soll ausschließen, daß wir
nichtnormal verteilte Daten fälschlich als solche ansehen: Wir
brauchen also ein kleines "Konsumentenrisiko", also einen kleinen
![]() -Fehler. Man geht mit einer
-Fehler. Man geht mit einer ![]() davon aus,
daß für ein
Signifikanzniveau von
davon aus,
daß für ein
Signifikanzniveau von ![]() der
der ![]() -Fehler klein genug ist.
Dies ist hier auf jeden Fall mit 96% ausgewiesen.
-Fehler klein genug ist.
Dies ist hier auf jeden Fall mit 96% ausgewiesen.
Die nächsten Aufgaben betreffen verschiedene Mittelwertvergleiche.
Bei abhängigen (gepaarten) Stichproben und
bei normalverteilten Merkmalen verwende man
Bei unabhängigen Stichproben und
bei normalverteilten Merkmalen verwende man
3.]
Laden Sie die Daten von Z:rheuma.sav. Es soll geprüft
werden, ob die Merkmale für ![]() 2-Globulin Lc10
2-Globulin Lc10![]() und Lc10
und Lc10![]() Mittelwertunterschiede aufweisen.
Mittelwertunterschiede aufweisen.
Anleitung: Zuerst ist zu prüfen, ob beide Merkmale normalverteilt sind
(KS-Test). Nutzen Sie dabei die Option ![]() Fallweiser
Ausschluß.
Fallweiser
Ausschluß.
Für den Test selbst verwende man den T-Test bei gepaarten Stichproben.
Die Antwort soll zu einem Signifikanzniveau ![]() =0.05 erfolgen.
=0.05 erfolgen.
Beim KS-Test ist bei ![]() Optionen
Optionen
![]() Fallweiser Ausschluß anzuklicken. Damit soll
gesichert werden, daß nicht Datenzeilen mit fehlenden einzelnen
Werten den Test verfälschen.
Der KS-Test ergibt die beiden Werte (für 2-Tailed P ) von 0,334 und
0,605. Der erstere ist nicht ganz 0,4, aber man gehe davon aus, daß
trotzdem noch näherungsweise eine Normalverteilung vorliegt.
Fallweiser Ausschluß anzuklicken. Damit soll
gesichert werden, daß nicht Datenzeilen mit fehlenden einzelnen
Werten den Test verfälschen.
Der KS-Test ergibt die beiden Werte (für 2-Tailed P ) von 0,334 und
0,605. Der erstere ist nicht ganz 0,4, aber man gehe davon aus, daß
trotzdem noch näherungsweise eine Normalverteilung vorliegt.
Der T-Test für den Mittelwertvergleich zweier gepaarter Stichproben
verwendet die direkten Differenzen ![]() aller einzelnem Ausprägungen für
alle
aller einzelnem Ausprägungen für
alle ![]() besetzten Zeilen. Die Test-Statistik ist dann
besetzten Zeilen. Die Test-Statistik ist dann