Eine Stichprobe von n=100 soll diese Nullhypothese überprüfen. Berechnen Sie zum Signifikationsniveau
Anleitung: Im Intervall von 0 bis 1/3 für p
Für die Varianz gilt näherungsweise
Skalieren Sie noch probeweise den p-Bereich auf Standardwerte z.
Hinweise zur 10. Übung - Stichproben -
1.] a) Ein Massenartikel ( N![]() 15000 ) habe eine
NORMAL-verteilte Ausschußrate von p=10% (Nullhypothese).
15000 ) habe eine
NORMAL-verteilte Ausschußrate von p=10% (Nullhypothese).
Eine Stichprobe von n=100 soll diese Nullhypothese überprüfen.
Berechnen Sie zum Signifikationsniveau ![]() =0,05 den kritischen
Wert der Testgröße für n.
=0,05 den kritischen
Wert der Testgröße für n.
Anleitung: Im Intervall von 0 bis 1/3 für p![]() für ein p(i) mit
i=1,...,301 Werten
die Dichte der Normalverteilung direkt berechnen; und diese bis zum
kritischen Wert 0,95 aufsummieren.
für ein p(i) mit
i=1,...,301 Werten
die Dichte der Normalverteilung direkt berechnen; und diese bis zum
kritischen Wert 0,95 aufsummieren.
Für die Varianz gilt näherungsweise ![]() =p
=p![]() (1-p
(1-p![]() ) /n,
da erfüllt ist: n/N
) /n,
da erfüllt ist: n/N![]() 0,05.
0,05.
Skalieren Sie noch probeweise den p-Bereich auf
Standardwerte z.
Die Aufgabe soll die typische Situation einer Stichprobe nachspielen.
Bei hinreichend großem ![]() kann man davon ausgehen, daß der
Mittelwert der Stichprobe normalverteilt ist. Dies ist unabhängig davon,
wie die ursprüngliche Verteilung der N Daten war.
kann man davon ausgehen, daß der
Mittelwert der Stichprobe normalverteilt ist. Dies ist unabhängig davon,
wie die ursprüngliche Verteilung der N Daten war.
Das Intervall ergibt sich mit 301 Zeilen zu p=($casenum-1)/900 .
Man setze somit den Ausschuß-Anteil in einer Stichprobe als
Normalverteilung mit ![]() an.
Dies ist die Nullhypothese H
an.
Dies ist die Nullhypothese H![]() .
Da wir je definierte Stichproben betrachten, ist die Varianz wie in der
Aufgabe angegeben
.
Da wir je definierte Stichproben betrachten, ist die Varianz wie in der
Aufgabe angegeben ![]() =0.1 (1-0.1)/100=0.0009, also
=0.1 (1-0.1)/100=0.0009, also
![]() =0.03. Die Formel rührt her von der Annahme, daß eine
Binomialverteilung den Ausgang der Stichprobe leitet.
Die Variable
=0.03. Die Formel rührt her von der Annahme, daß eine
Binomialverteilung den Ausgang der Stichprobe leitet.
Die Variable ![]() kann über dem Intervall direkt aus der
Dichte der Normalverteilung berechnet werden.
kann über dem Intervall direkt aus der
Dichte der Normalverteilung berechnet werden.
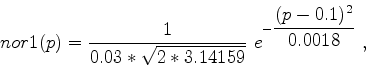
b) Die Alternativ-Hypothese der Ausschußrate sei p=20% .
Die Stichprobe von n=100 soll auch diese Hypothese überprüfen.
Berechnen Sie zu (a) den entsprechenden ![]() -Fehler.
-Fehler.
Anleitung: Im Intervall von 0 bis 1/3 für p![]() für ein p(i) mit
i=1,..., 300 Werte
die Dichte der Normalverteilung mit p=0,2 direkt berechnen; und bis zum
kritischen Wert von Aufgabe (a) aufsummieren. Für die Varianz gilt
nun näherungsweise
für ein p(i) mit
i=1,..., 300 Werte
die Dichte der Normalverteilung mit p=0,2 direkt berechnen; und bis zum
kritischen Wert von Aufgabe (a) aufsummieren. Für die Varianz gilt
nun näherungsweise ![]() =p
=p![]() (1-p
(1-p![]() ) /n.
) /n.
In b) soll nun noch der theoretisch denkbare Fall betrachtet werden,
daß die Alternativhypothese exakt zu ![]() =0.2 bekannt ist.
Mit
=0.2 bekannt ist.
Mit ![]() =0.2(1-0.2)/100=0.0016, also
=0.2(1-0.2)/100=0.0016, also
![]() =0.04 ergibt sich eine Dichte
=0.04 ergibt sich eine Dichte ![]() analog zu oben; und die
zugehörige Verteilungsfunktion. Dort kann man dann an der Stelle
p
analog zu oben; und die
zugehörige Verteilungsfunktion. Dort kann man dann an der Stelle
p![]() =0.149
der obigen kritischen Grenze einen Wert ablesen: 10.31 %.
(Das ist dann der
=0.149
der obigen kritischen Grenze einen Wert ablesen: 10.31 %.
(Das ist dann der ![]() -Fehler, wenn die Alternativhypothese gilt.)
-Fehler, wenn die Alternativhypothese gilt.)
c) Zeichnen Sie mit Hilfe von STREUPLOT die empirischen
Dichten für p=0,1 und p=0,2 übereinander. Welches sind die Gebiete der
![]() - und
- und ![]() -Fehler? Mit SequencePlot sind diese schraffierbar.
-Fehler? Mit SequencePlot sind diese schraffierbar.
Als ![]() Streudiagramm oder als
Streudiagramm oder als ![]() Liniendiagramm -
überlagert - über der Achse
Liniendiagramm -
überlagert - über der Achse ![]() können beide Dichten gemeinsam in
einer Abbildung gezeichnet werden.
Graphisch können
können beide Dichten gemeinsam in
einer Abbildung gezeichnet werden.
Graphisch können ![]() - und
- und ![]() -Fehler nur einzeln veranschaulicht
werden, wenn man für
-Fehler nur einzeln veranschaulicht
werden, wenn man für ![]() SequenzDiagramm entsprechende
Berandungs-Funktionen definiert:
SequenzDiagramm entsprechende
Berandungs-Funktionen definiert:
| H |
H |
H |
H |
| trifft zu | trifft nicht zu | ||
| trifft nicht zu | trifft zu |
2] Ein Massenartikel ( N![]() 15000 ) sei normalverteilt: Wir
betrachten die Mast von Hähnchen.
Der Mittelwert des Gewichtes sei
15000 ) sei normalverteilt: Wir
betrachten die Mast von Hähnchen.
Der Mittelwert des Gewichtes sei ![]() =492,5g bei einer
Standardabweichung von
=492,5g bei einer
Standardabweichung von ![]() =18,9g.
=18,9g.
Mit einer Stichprobe von n=81
Tieren ergibt ein Fütterungsversuch mit einem anderen Futter das
Resultat der Datei MASTHAHN.SAV.
Man kann annehmen, daß die Standardabweichung dabei nicht vom Futter
abhängt. Kann man auf Grund des Stichproben-Versuches schließen, daß
das neue Futter zu besseren Resultaten der Mast führt?
Die Antwort soll zu einem Signifikanzniveau ![]() =0.01 erfolgen.
=0.01 erfolgen.
Ist ![]() der Mittelwert einer Stichprobe
der Mittelwert einer Stichprobe ![]() , so nimmt man an,
daß dieser um den wahren Mittelwert
, so nimmt man an,
daß dieser um den wahren Mittelwert ![]() des Massenartikels
des Massenartikels ![]() schwankt.
schwankt.
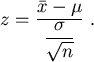
|
|
0,75 | 0,9 | 0,95 | 0,975 | 0,99 | 0,995 | 0,9975 | 0,999 |
| z | 0,674 | 1,282 | 1,645 | 1,960 | 2,326 | 2,576 | 2,807 | 3,090 |
In SPSS kann die Stichprobe auch mittels ![]() Analysieren,
Analysieren,
![]() Explorative Datenanalyse
betrachtet werden.
Dabei kann zu den Daten der Mittelwert, und der Wert
Explorative Datenanalyse
betrachtet werden.
Dabei kann zu den Daten der Mittelwert, und der Wert
![]() als der sogenannte Standardfehler berechnet werden. Weiterhin
kann bei der
als der sogenannte Standardfehler berechnet werden. Weiterhin
kann bei der ![]() Explorativen Datenanalyse im Feld
Explorativen Datenanalyse im Feld
![]() Statistik ein
Konfidenzintervall von 99% direkt eingestellt werden.
Es ist der Standardfehler 0.267 und das 99% CI ist [490.88;501.77].
Die leichte Abweichung der Zahlen deutet darauf hin, daß
Statistik ein
Konfidenzintervall von 99% direkt eingestellt werden.
Es ist der Standardfehler 0.267 und das 99% CI ist [490.88;501.77].
Die leichte Abweichung der Zahlen deutet darauf hin, daß
![]() etwas
verschoben ist, in der Tat ist in der Stichprobe
etwas
verschoben ist, in der Tat ist in der Stichprobe ![]() = 18.562.
(Man beachte, daß in SPSS die sogenannte empirische Varianz
= 18.562.
(Man beachte, daß in SPSS die sogenannte empirische Varianz ![]() mit dem Faktor 1/(n-1) verwendet wird.)
mit dem Faktor 1/(n-1) verwendet wird.)
Obwohl der Fütterungsversuch mit einem anderen Futter einen etwas
höheren Mittelwert der Gewichte der Hähnchen erbracht hat, kann diese
Änderung noch nicht als signifikante Verschiebung des Mittelwertes
betrachtet werden, da ![]() im CI liegt. Die Sache mit dem neuen
Futter muß also noch weiter untersucht werden. Eine (im allgemeinen
teure) Version der Weiterbetrachtung ist die Vergrößerung des
Stichprobenumfanges
im CI liegt. Die Sache mit dem neuen
Futter muß also noch weiter untersucht werden. Eine (im allgemeinen
teure) Version der Weiterbetrachtung ist die Vergrößerung des
Stichprobenumfanges ![]() , womit natürlich
, womit natürlich
![]() kleiner wird.
kleiner wird.