Lösungs-Hinweise 2. Übung - Verteilungsfunktion
1. In zwei vierten Klassen (A und B) ergab eine Klassenarbeit die
folgenden Zensuren:
| Klasse A | ||||||
| Note | 1 | 2 | 3 | 4 | 5 | 6 |
| Anzahl | 5 | 9 | 13 | 3 | 0 | 1 |
| Klasse B | ||||||
| Note | 1 | 2 | 3 | 4 | 5 | 6 |
| Anzahl | 3 | 6 | 10 | 2 | 1 | 2 |
a) Bestimmen Sie die empirischen Verteilungen ![]() und
und ![]() von beiden
Zensurenspiegeln.
von beiden
Zensurenspiegeln.
In drei Spalten sind die Werte der Tabelle einzutippen:
Note, Anzahl![]() , Anzahl
, Anzahl![]() . Mit
. Mit
![]() und
und
![]() gibt es das richtige Fenster.
Wir schieben die Variablen Anzahl
gibt es das richtige Fenster.
Wir schieben die Variablen Anzahl![]() und Anzahl
und Anzahl![]() ins obere rechte
Fenster.
Dies ergibt nach Ausführen neue Variablen Summe
ins obere rechte
Fenster.
Dies ergibt nach Ausführen neue Variablen Summe![]() und Summe
und Summe![]() ,
in der die Werte des Zensurenspiegels kumulativ aufaddiert sind.
,
in der die Werte des Zensurenspiegels kumulativ aufaddiert sind.
Teilt man diese Variablen in
![]() durch den kumulativen Wert in der 6.Zeile: also bei A durch 31 und
bei B durch 24, so ergeben sich die
empirischen Verteilungsfunktionen
durch den kumulativen Wert in der 6.Zeile: also bei A durch 31 und
bei B durch 24, so ergeben sich die
empirischen Verteilungsfunktionen ![]() und
und ![]() .
.
b) Zeichnen Sie beide empirische Verteilungen ![]() und
und ![]() in einem Koordinatensystem.
in einem Koordinatensystem.
Mit ![]() können die empirischen Verteilungsfunktionen beide dargestellt
werden, indem noch
können die empirischen Verteilungsfunktionen beide dargestellt
werden, indem noch
![]() gewählt wird.
Die Abszisse sollte der richtige Wert der Note sein.
Also ist einzustellen: Werte einzelner Fälle, und im Fenster ist dann die
Note für die Kategorienbeschriftung einzustellen.
gewählt wird.
Die Abszisse sollte der richtige Wert der Note sein.
Also ist einzustellen: Werte einzelner Fälle, und im Fenster ist dann die
Note für die Kategorienbeschriftung einzustellen.
c) Bestimmen Sie die Differenz der Verteilungsfunktionen
Wir berechnen die neue Variable Di:
![]() und Aufruf der Funktion ABS( ) im rechten Fenster: In die Klammern
werden die Variablen
und Aufruf der Funktion ABS( ) im rechten Fenster: In die Klammern
werden die Variablen ![]() geschoben.
Das Maximum von Di kann bei 6 Werten leicht abgelesen werden; sind es
mehr Fälle, so kann mit
geschoben.
Das Maximum von Di kann bei 6 Werten leicht abgelesen werden; sind es
mehr Fälle, so kann mit
![]() in Statistik der Punkt Maximum der entsprechenden Variablen Di
angeklickt werden. Es ergibt sich: D=0.093.
in Statistik der Punkt Maximum der entsprechenden Variablen Di
angeklickt werden. Es ergibt sich: D=0.093.
2. Gegeben sei die stetige Dichte ![]() einer Zufallsvariablen X
einer Zufallsvariablen X
Zuerst muß dem SPSS-System mitgeteilt werden, wieviele "Fälle" zu
bearbeiten sind. Dies geschieht am leichtesten durch Anklicken des
Datenkästchens in der 1.Spalte, 99.Zeile. Danach kann die Variable x
wie in der Aufgabe angegeben berechnet werden, und danach schon die Funktion
f(x). Da außerhalb des Intervalls [0.1,9.9] der Funktionswert Null sein
soll, ist keine Fallunterscheidung notwendig!
f(x) kann mit
![]() oder
mit -
oder
mit -![]() Streudiagramm
dargestellt werden (man verwende Werte einzelner
Fälle (!) über x
Streudiagramm
dargestellt werden (man verwende Werte einzelner
Fälle (!) über x![]() ) .
) .
Die Verteilungsfunktion F(x) ist die aufintegrierte Dichte:
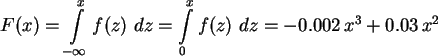
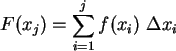
b) Berechnen Sie Erwartungswert ![]() und Varianz
und Varianz ![]() direkt, als auch mit SPSS.
direkt, als auch mit SPSS.
Es ist
![\begin{displaymath}
E\,x = \int\limits_0^{10} x\,f(x)\,dx = \int\limits_0^{10} ...
...^3 +
0.06 x^2 ) \, dx = [ -0.0015 x^4 + 0.02 x^3 ]_0^{10} = 5
\end{displaymath}](img25.png)
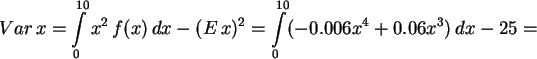
In SPSS sind die Integrale durch Untersummen anzupassen. Diese werden
wieder durch kumulative Summen berechnet.
Hinweis: Multipliziert man künstlich ![]() z.B. mit 1000,
so kann man auch wieder mit Gewichten arbeiten,
siehe No2 von Übung1
z.B. mit 1000,
so kann man auch wieder mit Gewichten arbeiten,
siehe No2 von Übung1
Für diese Variante erzeugen wir aus f(x) eine neue Spalte "Gewichte",
die größer als Eins sein sollen.
Die Spalte f(x) kann mit etwa 1000 multipliziert werden.
Unter ![]() und
und ![]()
kann diese Variable
als Gewicht für weitere Berechnungen verwendet werden. Dabei wird so
verfahren, als ob jeder Wert der Realisierung (dies ist die Achsenvariable
![]() ) so oft auftritt, wie sein Gewicht angibt.
In
) so oft auftritt, wie sein Gewicht angibt.
In
![]() schiebt man die Variable x in rechtes Fenster, und klickt in
schiebt man die Variable x in rechtes Fenster, und klickt in
![]() Mittelwert und Varianz an.
Es ergibt sich analog: Ex=5, Varx=4.9985 .
Mittelwert und Varianz an.
Es ergibt sich analog: Ex=5, Varx=4.9985 .